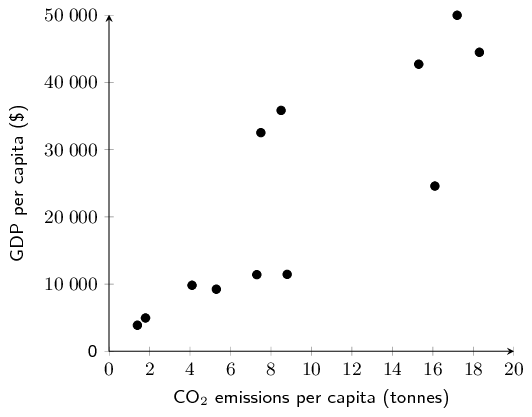
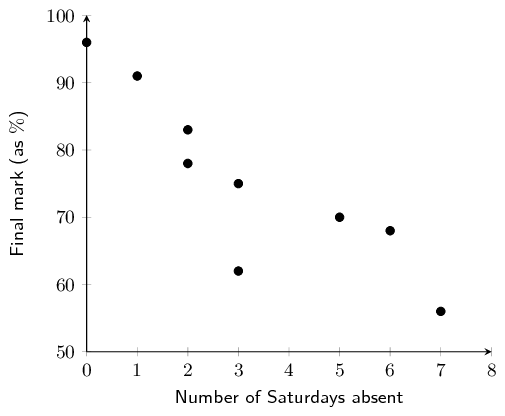
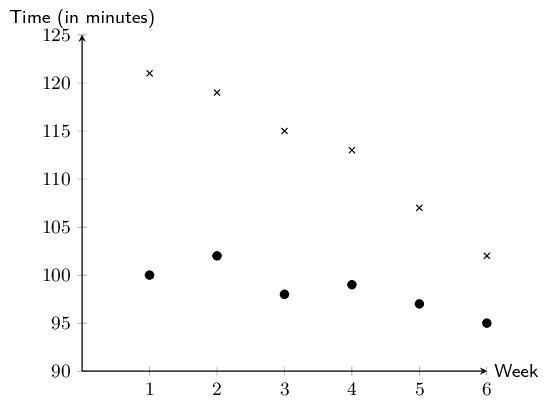
Draw a scatter plot of the data sets. Include Grant and
Christie's data on the same set of axes. Use a \(\bullet\) to denote
Grant's data points and \(\times\) to denote Christie's data points.
Convert all times to minutes.
Comment on and compare any trends that you observe in the
data.
Both data sets show negative, linear trends. The trend in Grant's
data appears to be more rapidly decreasing than the trend in
Christie's data.
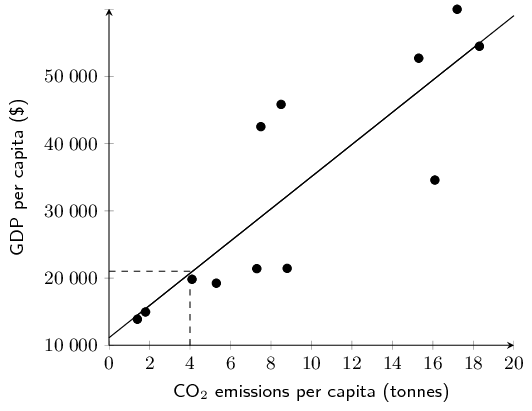
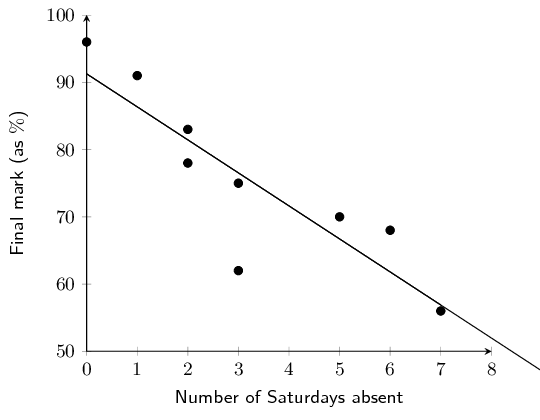
Determine the equations of the least squares regression
lines for Grant's data and Christie's data. Draw these lines on your
scatter plot. Use a different colour for each.
\begin{align*}
\hat{y}_{\text{Grant}}&= \text{126,13} -\text{3,8}x \\
\hat{y}_{\text{Christie}}&= \text{102,4} - \text{1,11}x
\end{align*}
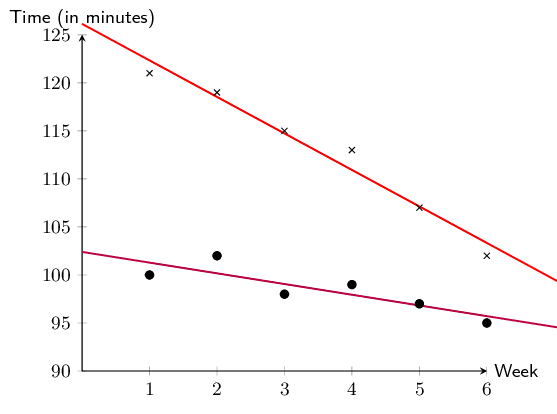
Calculate the correlation coefficient and comment on the
fit for each data set.
\begin{align*}
\text{Grant: } r&= -\text{0,98} \quad \text{(negative, very strong)}
\\
\text{Christie: } r&= -\text{0,86} \quad \text{(negative, strong)}
\end{align*}
Assuming the observed trends continue, will Grant beat
Christie in the race?
Grant will beat Christie when \(\hat{y}_{\text{Grant}} <
\hat{y}_{\text{Christie}}\). To find where the trends intersect,
we equate each \(\hat{y}\).
\begin{align*}
\text{126,13} -\text{3,8}x &= \text{102,4} - \text{1,11}x \\
-\text{3,8}x + \text{1,11}x&= \text{102,4} - \text{126,13} \\
-\text{2,69}x &= -\text{23,73} \\
x &= \text{8,82}
\end{align*}
The race takes place in week 8. \(\text{8,82} > 8\), therefore,
Grant will be unable to beat Christie's time when the race takes
place.
Assuming the observed trends continue, extrapolate the week
in which Grant will be able to run a half-marathon in less time than
Christie.
See answer to e). Grant will be able to beat Christie's time in the
ninth week.